
近几年人工智能风靡,诸多大中小企业纷纷布局,对于创业公司来说,想要有所建树,深耕垂直细分领域才是关键。因为这里有大量的行业背景知识,即使巨头投入巨资也需要先摸清行业情况,这个过程往往需要一年或更多,这就为创业公司赢得了大量的时间机会。对于这一类的情况,巨头可能更倾向于收购或注资,而不是自建团队。
三年来,学霸君在教育行业积累很多行业知识,尤其在校内业务方面,对学校的情况非常熟悉。同时,因校内业务的需求,学霸君一直非常注重人工智能相关技术的研发。通用人工智能技术非常难做,但与垂直行业场景结合起来,降低算法的难度,使得算法找到用武之地。在这个过程中,踩了很多坑,也收货了丰富的实践经验。本文将介绍学霸君在校内业务所的几大应用:结构化题库建设、自动解题与知识图谱、作业自动批改、自适应学习。
题库是教育公司的核心之一,市面上绝大部分题库,题目的数据都是一段简单的字符串。为了真实还原题目的结构,学霸君选择使用json来描述题目的结构,一道题由很多零件根据一定的规则组合而成。
如下图所展示的选择题,由题干描述部分和选项部分组成,选项分成4个,题干上有填空的位置,有每一个公式的位置标记。用json结构来记录题目结构,可以把大题拆成小题,可以精准定位每一个填空的位置,等等。这样的题库可以给产品设计提供更多更灵活的使用条件。

这种数据结构给题目的应用带来了好处,但也增加了题库生产的成本,因为题目的录入环节需要对题目做结构拆分与关联。为了降低成本,学霸君采用大量的图像识别算法。
如下流程图是一个简化的题目录入流程,从图中可以看到,很多关键环节都相应地使用了识别算法来提高效率。
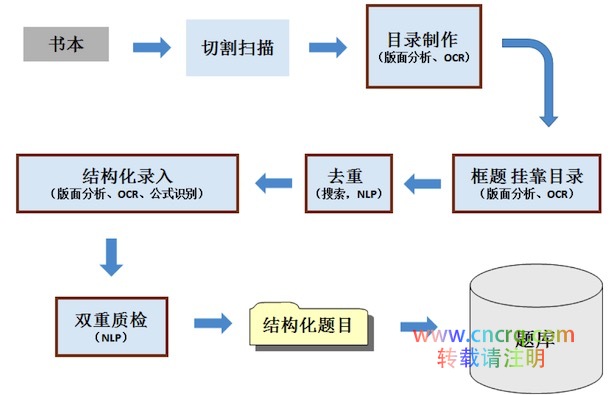
例如,在结构化录入环节,我们使用了版面分析、OCR、公式识别等算法,所有题目都会经过算法先识别出一个初步的结果,录入人员人工审核结果,如果正确就直接跳过,有错误就局部修改,这样可以大大提高录入人员的效率。目前题库生产系统,对于任意一本教辅书,可以做到一天内完成所有题目的结构化加工生产到入库,如果没有系统和算法的支持,这几乎是不可能的。
除了题目结构问题之外,理科题目的公式也是一个重要点。因为公式的结构和排版比较复杂,所以很多题库都采用了截图的方式存储公式,这种方法丢失了公式的内容信息,并且存在图像缩放影响美观的问题。
学霸君采用LaTex存储公式的方案,LaTex是一种通用的排版规范,可以适用于各种排版的场景。我们针对K12中出现的所有公式和符号,制定了一套基于LaTex的展示标准,基于这套标准,优化了MathJax开源工具,使得web端JS渲染的质量和效果都达到理想要求。
除了JS渲染工具,学霸君还开发了基于C语言内核的LaTex渲染工具,进一步封装成安卓和iOS版本SDK。它的原理是解析LaTex文本并转义成SVG矢量图,然后再交给web页面来渲染成最终结果。C语言内核的SDK的渲染速度比JS快几倍,特别适用于学校大规模使用的低端PAD。

采用LaTex来存储公式,就需要在录入题目的时候把题目录成LaTex格式,这个人工成本很大,尤其需要算法的帮助。
以往公式识别的算法,都是先通过一些图像处理的手段,把公式切割成单个字符,然后分别识别每一个字符,最后再通过二维空间的结构关系,把字符组合成公式。这一类算法有很多局限性,字符有粘连的情况无法很好处理,基于空间结构的组合随着深度增加,计算复杂度程几何数量级增长,加上字符有可能有识别错误,导致无法从海量候选列表中找到正确的结果。
学霸君使用了端到端的识别方法,避免了以上所有问题,输入是一个整体的图像,输出就是基于LaTex结构的公式的识别结果。算法的神经网络结构是CNN(卷积网络)+BLSTM(双向长短记忆模型)+CTC(时序分类)。
为了训练模型,学霸君在学校采集了大量的学生手写公式数据,并标注为LaTex结构。这种网络模型目前也有局限性,对于十分复杂的公式也是无法识别准确的,对于格式过于复杂的公式,我们通过空间结构关系将其拆分为若干个简单的公式,然后分别使用端到端的手段来识别,最后组合在一起。
除了结构化格式外,学霸君还希望题库的每一道题都能说清楚用到了什么知识点,甚至希望知道解题过程的每一个步骤都用到哪些知识点。如果每一题每一个步骤都由人来标记知识点,是无法完成的,希望通过算法代替人工来实现,这就用到了自动解题技术。自动解题大体分为三个步骤:理解、推导和表达,整体流程如下图所示。
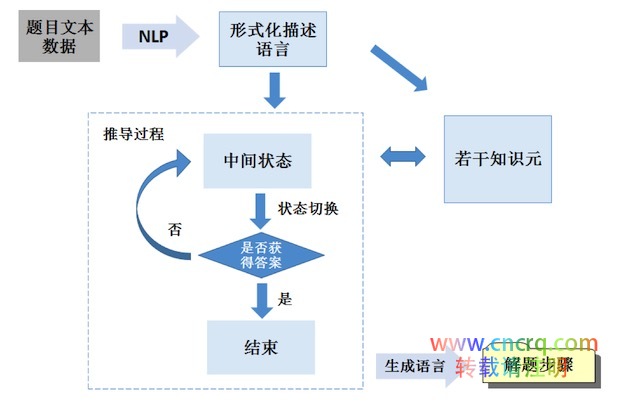
首先理解题干的语义,将题干内容从自然语言翻译成形式化的语言,也就是NLP的过程。开放的语义理解是科研界的难题,至今也距离实用甚远。但在中学理科体系里,语言的表达往往十分规范,这就大大降低了NLP的难度。
更重要的是,在开放的语义理解场景,是无法定义评判标准的,缺少客观标准,会给训练带来巨大难度。但在中学理科体系里,很容易定义对错,结合大量的数据,可以训练出比较理想的模型。
题目中经常会遇到公式,前文提到我们题库中的题目公式都是统一定义和规范的LaTex格式的,这就保证了机器可以准确地识别公式内容。
接下来是解题步骤的推理过程。需要根据当前所有条件,获取所需要的知识元信息。知识元是我们定义的最小细分的知识点,一个知识元是该知识点的定义和特征的总和,例如一个圆可以作为一个知识元,它有直径、半径、周长、面积等属性,当我们知道它的直径,可以进而计算出它的半径、周长和面积。简单理解,一个知识元就是一个小知识点。
将当前所有条件综合到一起,当做初始状态。根据当前所有知识元的特性可以进行步骤推导,获得新的条件,进而状态不断变化。每一次推导都有很多种可能性,哪种推导最优由模型根据题干的问题来决定。
每次状态切换后,比对一下是否获得最终答案,如果获得答案则推导过程结束。推导过程和知识元是密切相关的,同时中间状态发生的条件变化,也会引入新的知识元。
最后是表达过程,也就是将推导的过程翻译成标准解题步骤,同时从几个不同维度输出关键信息。例如,每一个推导的步骤都会标记上所使用的知识点;在所有的步骤中,根据该题所有知识元的情况,找到几个最重要的步骤作为关键步骤;综合该题的所有知识元,概括出本题考察的教研层面的知识点(教研知识点是从老师角度观察的知识点,与解题算法中的知识元不是一个维度)。
为了实战验证自动解题技术的效果,将解题技术封装成高考机器人,在2017年6月高考当天,我们的高考机器人和广大学生一起参加了高考,在高中数学取得了134分的成绩,这是人工智能技术落地在教育行业的一个重要突破,引起了包括央视在内的各大媒体的关注和报道。
有了自动解题技术,我们就可以给所有题目标注知识点。教研老师与技术同学一起制定一套覆盖所有知识点的四级知识体系,知识点之间有层级关系,也有依赖或关联关系,呈一个网状结构。
这个知识体系与我们的题库可以通过自动解题技术关联起来,形成一个知识图谱。在这个知识图谱中,每一题都可以关联到若干个知识点,每一个知识点也可以关联到若干个题目。有了知识图谱,系统就可以自动为每次学生作业和考试生成学习报告,从知识点的各个维度剖析学生的掌握情况。
在学校的调研中,学霸君发现老师批改作业的负担十分繁重,希望通过系统来帮助老师批改作业,解放老师的时间和精力。如果实现系统批改作业呢?
首先需要收集到学生的手写作业数据,我们通过点阵数码笔来实现。点阵数码笔需要在普通纸张上印刷一层几乎不可见的点阵图案,数码笔前端的高速摄像头随时捕捉笔尖的运动轨迹,同时结合压力传感器将数据收集到处理器,通过编码翻译将点阵图像翻译为笔迹的坐标位置,最终将笔迹信息通过蓝牙传输到PAD上。
如下图所示,学生使用点阵数码笔做作业或考试,不改变在纸上写字的传统习惯,同时可以实时将笔迹数据电子化。

获取到学生手写数据后,先通过版面图像处理技术将手写数据拆解成文本行,然后通过联机手写识别技术来识别出每一行的文字。
联机手写识别同样用到CNN(卷积网络)+BLSTM(双向长短记忆模型)+CTC(时序分类)的模型,但具体的实现与前面的公式识别场景不一样,特别是CNN的输入图像序列部分,学霸君采用了华南理工大学金教授论文里的Path-signature特征作为CNN的输入特征图序列。
对于复杂排版公式,同样先拆分成简单文本行,识别后再组合起来。采用学生的真实手写数据来训练,实践证明,真实场景数据比我们雇佣人力来写的效果要明显好。
只识别出学生手写笔迹,还无法完成自动批改,因为标准答案是有很多种变形的,同一个标准答案,不同的表达方式可能都是正确的,例如图上的这个例子。一个答案往往是有十几种变形的,这背后需要有大量的教研基础知识,系统识别出标准答案后,通过数学符号语言处理等算法,自动生成所有的同义表达式。将学生笔迹的最终答案,与标准答案的所有同义表达式进行匹配比较,找到结果一致的表达式。匹配的过程还需要考虑到,学生笔迹的最终答案有可能有一些冗余文字。
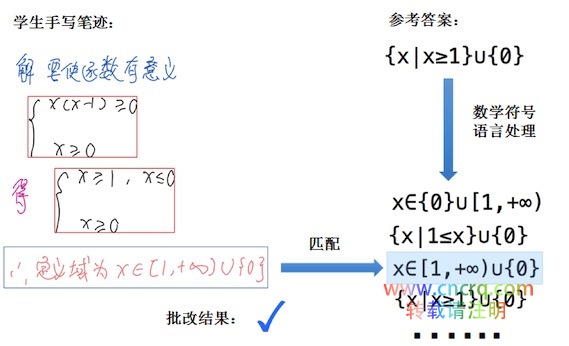
对于解答题,还希望能根据步骤来批改,想做到这一点是非常困难,学霸君采用关键步骤匹配的折中方案。通过自动解题技术,可以获得解题过程的关键步骤,为了提高批改准确率,只选择少量关键步骤,将关键步骤与学生的解题步骤进行匹配。最终题目的得分由关键步骤的分数和答案的分数加和而得。
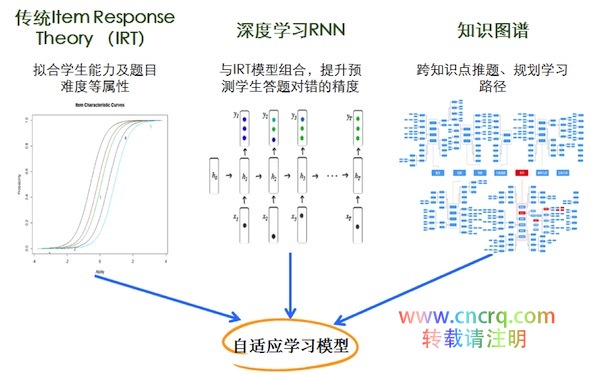
随着学生持续使用学霸君的题库做题(作业、考试等),系统可以持续收集到学生的学习行为数据,有了这些数据就可以做到自适应学习,也就是个性化学习。这里用到IRT的传统模型,IRT理论即项目反应理论(Item Response Theory),又称题目反应理论,是一系列心理统计学模型的总称。IRT是用来分析考试成绩或者问卷调查数据的数学模型,目前广泛应用在心理和教育测量领域。
通过IRT模型,结合大量学生做题数据,可以分析出每一道题目的难度以及学生的能力,结合知识图谱体系,进一步分析出学生在每个知识点的能力情况,也就是学生的知识点能力模型。有了这个模型,对于任何一道新题目,可以预测出学生做对这道题的概率,这样,就可以给学生推荐难度适中适合他的题目,太简单或太难的题就没必要浪费时间了。
对于行为数据丰富的地区和学科知识模块,可以直接用RNN模型来训练,输入的是学生的做题序列特征数据,输出的是每一题的正确与否的预测。当数据量较大并且比较均匀的时候,RNN模型的效果才会相对理想。随着用户行为数据的不断收集,以及用户对产品的越来越规范的使用,相信RNN模型是未来的方向。
以上是学霸君将人工智能算法与教育行业结合的一些探索,一些算法看起来比较难,但在垂直场景下使用得当,与工程项目深度融合,是可以获得比较理想的效果的。学霸君始终认为,人工智能在创业公司里的落地,离不开与业务场景的深度融合。我们的算法工程师不仅可以写代码,也能做卷子参加考试,只有这样才能保持特有的竞争力,在行业内有所突破。

苗广艺,中科院硕士研究生,先后就职于搜狐、YY、奇虎360。现担任学霸君技术副总裁,负责人工智能相关算法的研发推进,以及基础技术在业务场景的落地实施。带领团队在国内率先研发出适应手机拍照各种复杂场景的文字识别算法,为学霸君题库与教研体系搭建基础数据结构和算法服务,并将其应用于各条业务线,同时带领Ai学智慧教育平台技术团队研发了自动批改、自适应学习等多项前沿技术,为Ai学业务奠定了技术基础。
