任何事物都有它的两面性,索引也不例外,本文我们就来阐述一下索引的坏处。这里我们先简要综述一下索引的不足之处有哪些,而后详细阐述,随后一起和大家探索各种工作中的案例,最后为思考回顾。
总体学习思路如下图所示:
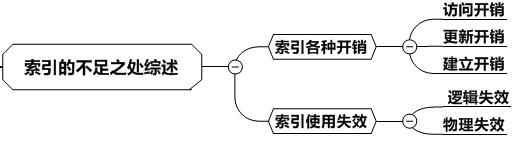
关于索引的不足之处,我们可以从索引的开销和容易失效这两个方面来讨论,如下图所示:
还记得前面关于索引结构的分析吗?通过系列步骤,我们明白了索引的结构,推导出索引的三大特性,并应用这些特性让SQL跑得更快。这只是索引好的一面。真正有问题的一面被掩盖了。那到底都有什么问题?
1.热块竞争
你看,索引最新的数据块一般是在最右边,而我们访问数据时正常来说也是访问比较新的数据,历史数据很少有人关注。然而问题来了,大家都一起访问最新的数据,不就都集中于同一个目标来访问了吗?这就很容易产生热块竞争。
2.回表开销
另外,大家都知道索引存储索引列的值和rowid,通过rowid来定位回到表中。其实这个回到表中的开销也是很大,具体情况我们随后可以了解到。
3.更新开销
索引的有序性是一个非常重要的特性,这个特性能够消除排序等开销,但是索引块要保持有序性,可不是一件容易的事。毕竟索引列的数据是随机插入的,比如你在原来的索引列中存储的是100、110、111等等时,现在要插入101,就应该在100和111之间插入,为了保证这个顺序索引需要做很多事,比如索引块分裂。而索引列的增删改的开销是很大的。
4.建立开销
还有千万别忽略了建立索引的开销,这也和索引的有序性有关。我们在建索引的过程中,首先把索引列的数据排序提取出来,再插入到块中形成索引块,这时如果数据不断地插入,排序提取这个动作什么时候能结束呢?所以还必须要锁表,这就是一个很大的开销(Online建索引是一种特殊的思路,这里不做描述)。当然建索引过程中排序这个动作本身也是一个不小的开销。
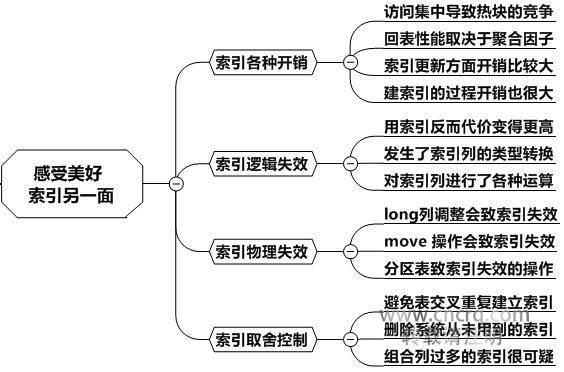
索引的不足之处除了上述的几点外,从另一个维度看,还会有失效的可能。我们现在知道建索引对查询一般比较有利,对更新一般比较有害。不过有的时候,虽然建了索引,但其对查询毫无帮助,这种情况还是有的。比如索引失效了,这分为逻辑失效和物理失效两种。
1.逻辑失效
逻辑失效是索引本身并没有真正失效,只是由于写法的问题导致索引用不上,比如对SQL的条件列进行运算,类似select * from t where upper(name)=‘ABC’等,这时在name列上建了Btree索引是用不上的。再或者比如被人强制用了全表扫描的Hint等导致数据库被迫不用索引等。
2.物理失效
物理失效就是索引真的失效了,比如被人误设了unusable动作,或者是一些类似分区表的不规范操作导致的索引失效。对此后续有详细的例子说明。
前面简要描述了索引的不足之处,接下来我们进行更加详细的展开说明,具体细节如下:
由于一般来说,最新的值都是最新产生的,所以访问它容易产生热块竞争。举例来说,如: select * from t where id=100000,select * from t where id=99999;select * from t where id=99998;select * from t where id=99997;这些数据很可能是相邻的,那么它们就会在同一个索引块上,这样很容易产生热点索引块竞争。
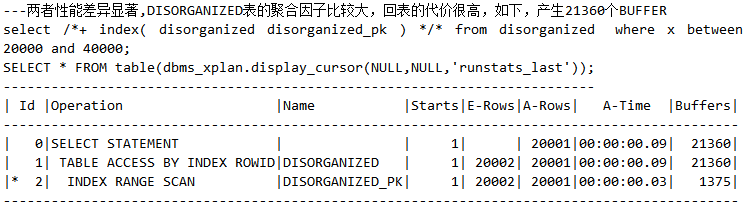
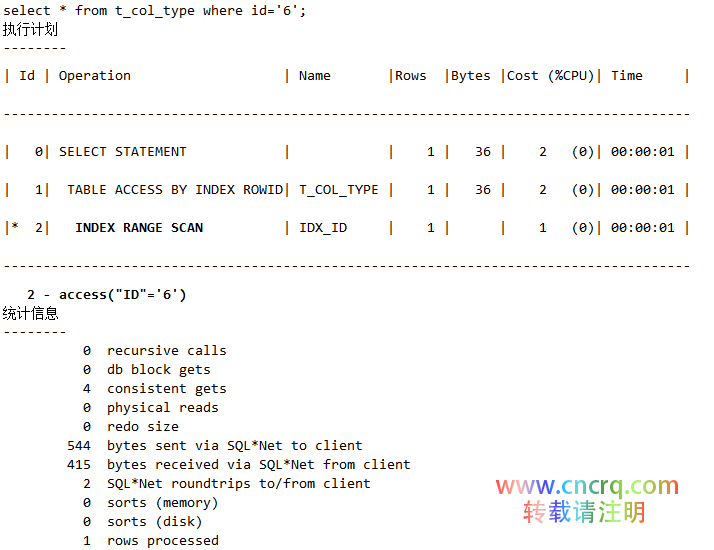
结论:索引查询要尽可能避免回表,如果不可避免,则需要关注聚合因子是否过大。(注:这个例子在前面的章节已经说过了,这里就不再详述了。)在该例子中,构造脚本organized表的聚合因子比较小,回表的代价较低,产生了2900个buffer,如下:
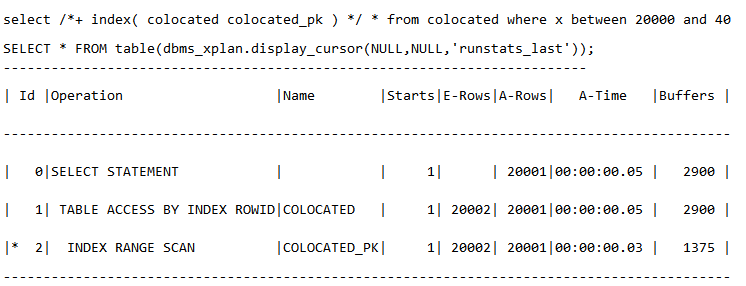
而disorganized表的聚合因子比较大,回表的代价很高,如下,产生21360个buffer:
环境搭建:
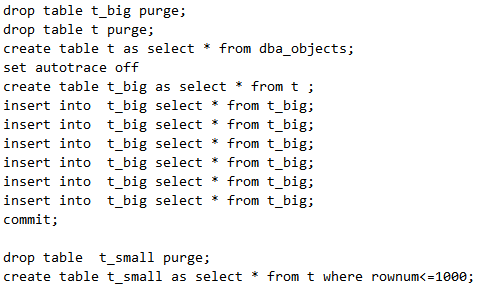
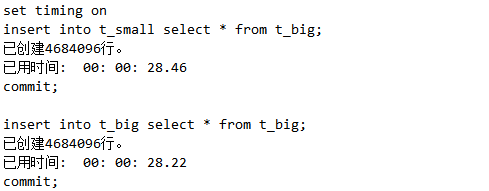
由上面代码可以看出,虽然t_small是小表,t_big是大表。但是插入一般不会随着记录的增加越插越慢。什么时候会越插越慢,就是当表有索引的时候。因为索引需要维护,越大维护越困难。我们继续做一组试验。
环境准备(建3张结构和记录都一样的表,只是索引分别是6个、2个及无索引):
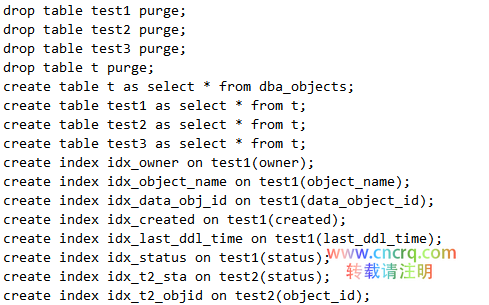
分别往这三张表里插记录:

表记录越大,索引越多,插入越慢,从试验结果来看,这一点还是非常明显的。
(1)建索引过程会产生全表锁
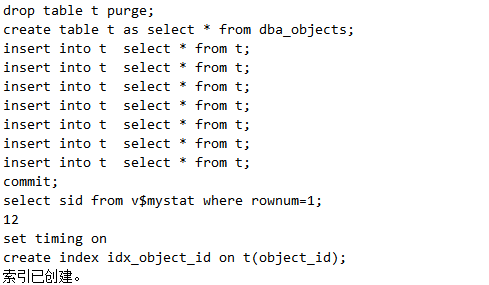

(2)建索引过程会产生全表排序
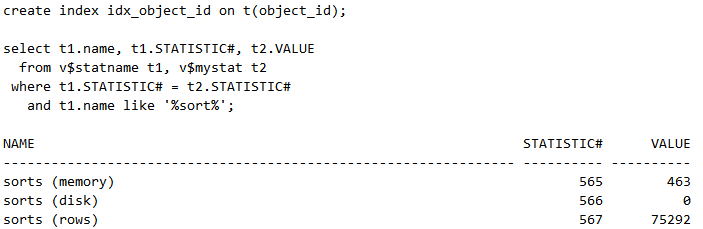
未建索引前,观察一下数字字典中记录的系统排序情况,如下:

建索引后,继续观察,发现排序次数sorts (memory)增加了,如下:

这个道理比较简单,如果应用索引范围检索数据,返回大量记录且几乎是所有的记录,这时候用索引肯定有错,索引范围查询访问一般适合返回少量记录的情况,否则用全表扫描或者全索引扫描就可以。
在表字段设计的时候有一个非常重要的原则,什么类型的字段存什么类型的值,否则就会发生类型转化。
实际上只有如下写法才可以用到索引,这个很不应该,如果什么类型的取值就设置什么样的字段,把ID字段类型改为Number,就顺畅了,如下:
对索引列进行了各种运算,详见后面的案例部分。
环境准备(建表,建long字段):
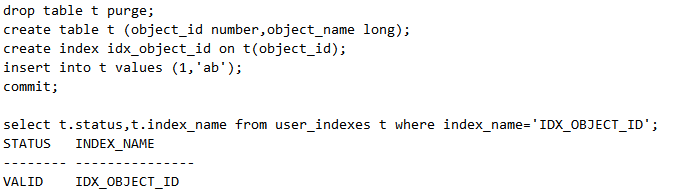
接下来将long修改为clob,发现索引失效了,必须重建索引,如下:
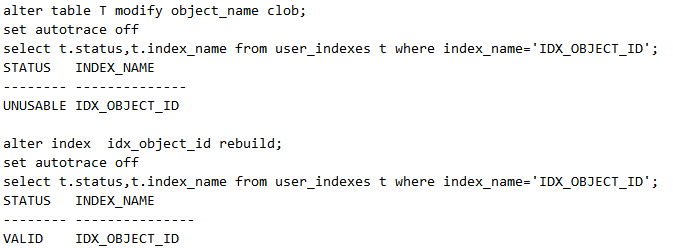
move是一个危险系数非常高的操作,虽然它可以收缩表降低高水平位,却会导致索引失效,因而需要重建索引。
这在前面已经描述过了,这里就不再重复了,请读者自行回到前面的章节进行复习总结。归纳如下:
truncate分区会导致全局索引失效,不会导致局部索引失效。如果对truncate 增加update global indexes,则全局索引不会失效。
drop分区会导致全局索引失效,局部索引因为drop分区,所以也不存在该分区的局部索引了。如果对drop分区增加update global indexes,全局索引不会失效。
split分区会导致全局索引失效,也会导致局部索引失效。如果对split分区增加update global indexes,则全局索引不会失效。
add 分区不会导致全局索引失效,也不会导致局部索引失效。
exchange会导致全局索引失效,不会导致局部索引失效。如果对exchange分区增加update global indexes,则全局索引不会失效。
所有的全局索引,只要用到update global indexes ,都不会失效,其中add分区甚至不需要增加update global indexes都可以生效。
局部索引的操作都不会失效,除了split分区。切记split分区的时候,要将局部索引进行rebuild。
假如t表有nbr、area_code两列的联合索引,单列的nbr索引就显得多余,因为nbr、area_code索引可以用在单列nbr索引上,具体如下:
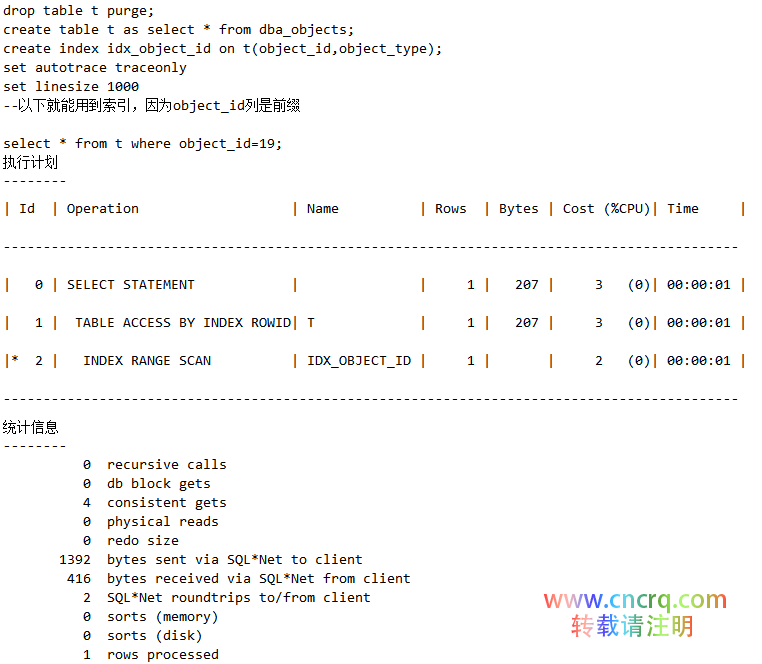
环境搭建,建表建索引并完成某列索引的监控:

接下来继续执行一个用索引的查询,然后再观察Used字段,发现索引被用过:

停止对索引的监控,观察v$object_usage状态变化,发现MONITORING的值为NO,且END_MONITORING记录了停止监控的时间,如下:

组合索引一般不宜过多,如果组合索引列达到4个以上,那这个索引本身就很大,就不一定高效。另外,索引更新也会出现比较大的性能问题。



评论